
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 독후감
- PRML
- 디지털마케팅
- 스플라인
- 오블완
- 책리뷰
- RStudio
- 제주2주살이
- R
- 에이바우트
- Jupyter notebook
- 티스토리챌린지
- 제주도
- GenAI
- Linux
- 클러스터형인덱스
- 혼공S
- 보조인덱스
- 스토어드 프로시저
- digital marketing
- 맛집
- 혼자공부하는SQL
- SQL
- 유럽여행
- 런던
- PRIMARY KEY
- 영국여행
- Github
- 김호연작가
- 제주도여행
- Today
- Total
Soy Library
[Hadoop] 빅데이터란? 본문
하둡에 대해 알아보기 전에 빅데이터라는 것에 대한 정의가 필요할 것 같다.
빅데이터에 대한 정의는 각 분야의 전문가마다 다르다. 맥킨지는 데이터 규모에 초점을 맞춰, 빅데이터라는 것을 '기존 DB 관리도구의 수집, 저장, 관리, 분석 역량을 넘어서는 데이터'라고 정의하였다. IDC(International Data Corporation)는 업무 수행 방식에 초점을 맞춰, 빅데이터를 '다양한 종류의 대규모 데이터로부터 가치를 추출하고, 데이터의 빠른 수집, 발굴, 분석을 지원하도록 고안된 기술 및 아키덱쳐'라고 정의하였다.
SNS나 스마트 기기의 확산으로 데이터 양이 기하급수적으로 증가하였고, 저장장치의 가격이 인하나 데이터의 처리 기술이 발달 등 여러 배경 덕분에 빅데이터가 출현했다고 볼 수 있다.
※ 데이터 용량
1024 byte = 1 KB
1024 KB = 1 MB
1024 MB = 1 GB
1024 GB = 1 TB
1024 TB = 1 PB
1024 PB = 1 EB (엑사바이트)
1024 EB = 1 ZB (제타바이트)
1024 ZB = 1 YB (유타바이트)
빅데이터는 3V의 특징을 가진다고 한다.
- Volume: 거대한 양
- Velocity: 빠른 데이터 유통 및 이용 속도
- Variety: 정형, 반정형, 비정형 등 다양한 형태의 데이터
빅데이터를 활용한 여러 대표적인 사례가 있다.
1. 미국의 경우 9.11 범죄 이후 국토안보부를 중심으로 테러 및 범죄 방지를 위한 범정부적 빅데이터 수집, 분석 및 예측체계를 도입하였다.
2. 월마트의 경우 월마트랩을 이용한 소비자 소비 패턴 조사를 통해 점포 운영에 반영하였고, 소셜 미디어를 통해 대규모 데이터를 수집하여 리얼타임으로 해석되어 추출된 정보를 이용하여 상품판매를 촉진하는 기법을 사용했다.
3. 일본의 경우는 평상시에 하루에 5만 건의 정보를 수집하여 한정된 지역에서 수시간 앞까지의 상황을 예측할 수 있다.
빅데이터의 에코시스템
빅데이터는 수집 > 정제 > 적재 > 분석 > 시각화의 여러 단계를 거치는데, 이 단계를 거치는 동안 여러가지 기술들을 이용하여 처리된다. 이러한 기술들을 통틀어 빅데이터 에코 시스템이라고 한다.
1. 빅데이터 수집 기술 (Data Aggregator)
- Flume: 클라우데라에서 개발한 서버 로그 수집 도구. 각 서버에 에이전트가 설치되고, 에이전트로부터 데이터를 전달받는 콜렉터로 구성됨.
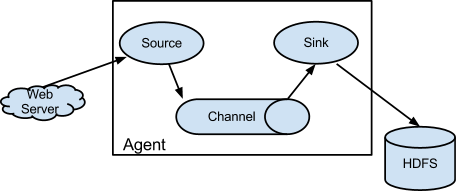
- Scribe: 페이스북에서 제작한 로그 수집 시스템. 메시지 큐에 쌓인 로그를 DB나 메시지 큐로 전달.
- Chukwa
- Kafka: Linkedln에서 개발한 분산 스트리밍 플랫폼. 메시징, 메트릭 수집, 로그 수집, 스트림 처리 등 다양한 용도로 사용할 수 있다. 발행 - 구독 - 메시징 시스템으로 동작함.
2. 데이터 저장 (Storage)
빅데이터는 대용량의 데이터를 저장해야하기 때문에 데이터의 저장의 안정성과 속도가 매우 중요하다. HDFS, AWS의 3S 등이 있다.
- HDFS (Hadoop Distributed File System): 하둡 프레임워크를 위해 자바 언어로 작성된 분산 확장 파일 시스템이다. HDFS는 여러 기계에 대용량 파일들을 나눠서 저장한다. 데이터들을 여러 서버에 중복해서 저장을 함으로써 데이터의 안정성을 얻고, 호스트에 RAID 저장장치를 사용하지 않아도 된다.
- Column 기반 파일 형식:
- RCFile: 하이브 테이블을 저장하기 위해 HDFS에 구현한 첫 번째 column기반 저장형식
- ORC:
- 파퀘이:
- NoSQL (cloudata, hbase, cassandra, mongodb): 비관계형 데이터베이스를 지칭하는 용어. 데이터 베이스는 선형적인 확장성과 성능, 고가용성, 유연한 스키마 등 다른 특성을 위해 ACID를 포기.
※ Atomicity: 원자성, Consistency: 일관성, Isolation: 고립성, Durability: 지속성
- Cassandra: 분산 및 확장이 가능하고 결함이 허용되는 NoSQL 데이터베이스. 마스터가 없는 분산 아키텍처.
- HBase: HDFS 기반의 column기반 NoSQL 데이터베이스. 관계형 데이터를 지원하지 않는 대신 클라이언트 애플리케이션이 데이터 저장을 동적으로 제어할 수 있음.
3. 데이터 직렬화 (Application Server)
빅데이터 에코 시스템이 다양한 기술과 언어로 구현되기 때문에 각 언어간에 내부 객체를 공유하는 경우에, 이를 효율적으로 처리하기 위해서 데이터 직렬화 기술이 필요하다. 직렬화란 데잍러르 파일로 저장하거나 또는 네트워크로 전송하기 위하여 바이너트 스트림 형태로 저장하는 행위이다.
- Avro: 아파치의 하둡 프로젝트에서 개발된 원격 프로시저 호줄(RPC) 및 데이터 직렬화 프레임워크이다. 자료형과 protocol 정의를 위해 JSON을 사용하며 콤팩트 바이너리 포맷으로 데이터를 직렬화한다.

- Thrift: 언어 독립적인 데이터 직렬화 프레임워크이다. 원격 프로시저 호출(RPC) 프레임워크를 형성하며 페이스북에서 "스케일링이 가능한 언어 간 서비스 개발"을 위해 개발된 것이다. 서로 다른 언어로 만들어진 어플리케이션 사이에 데이터를 직렬화하고 네트워크를 통해 전송하기 위한 라이브러리 세트를 제공한다.
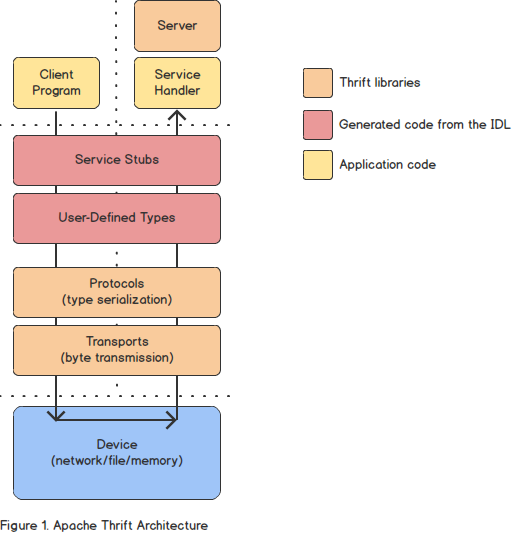
- 프로토콜 버퍼: 구글에서 개발한 RPC 프레임워크이다. 구조화된 데이터를 직렬화하는 방식을 제공한다. 다양한 언어를 지원하며 특히 직렬화 속도가 빠르고 직렬화된 파일의 크기도 작어서 avro 파일 포맷과 함께 많이 사용된다.
Reference
1-빅데이터란?
빅데이터는 **큰 사이즈의 데이터로부터 유의미한 지표를 분석해내는 것**으로 정의할 수 있습니다. SNS, 로그, 문서 등 다양한 경로를 통해 수집한 여러가지 형태의 많은 ...
wikidocs.net
https://ko.wikipedia.org/wiki/%EB%B9%85_%EB%8D%B0%EC%9D%B4%ED%84%B0
빅 데이터 - 위키백과, 우리 모두의 백과사전
빅 데이터(영어: big data)란 기존 데이터베이스 관리도구의 능력을 넘어서는 대량(수십 테라바이트)의 정형 또는 심지어 데이터베이스 형태가 아닌 비정형의 데이터 집합조차 포함한[1] 데이터로
ko.wikipedia.org
'Study > Hadoop' 카테고리의 다른 글
| [Hadoop] 하둡과 HDFS (0) | 2022.03.13 |
|---|
