
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 책리뷰
- 제주도여행
- 독후감
- PRIMARY KEY
- 스토어드 프로시저
- PRML
- 런던
- digital marketing
- 혼자공부하는SQL
- R
- 제주2주살이
- 제주도
- RStudio
- 오블완
- 영국여행
- 티스토리챌린지
- 김호연작가
- SQL
- Github
- 디지털마케팅
- Linux
- 클러스터형인덱스
- 보조인덱스
- 스플라인
- Jupyter notebook
- 에이바우트
- 혼공S
- 유럽여행
- GenAI
- 맛집
- Today
- Total
Soy Library
[혼공S] CH3-(2). 좀 더 깊게 알아보는 SELECT문 본문
이 절에서는 SELECT 문에서 결과 정렬을 위한 ORDER BY, 결과의 개수를 제한하는 LIMIT, 중복된 데이터를 제거하는 DISTINCT 등을 사용하는 법을 배운다.
또한 GROUP BY를 사용하여 지정한 열의 데이터들을 같은 데이터끼리는 묶어서 결과를 추출할 수 있도록 한다. 주로 합계, 평균, 개수 등을 처리하므로 집계함수와 같이 쓰이고 HAVING 절을 통해 조건식을 추가할 수 있다.
ORDER BY 절
먼저 기본적인 SELECT 절의 형식은 아래와 같다.
SELECT 열_이름
FROM 테이블_이름
WHERE 조건식
GROUP BY 열_이름
HAVING 조건식
ORDER BY 열_이름 -- **
LIMIT 숫자 -- **
member 데이터에서 데뷔일자가 빠른 순으로 mem_id, mem_name, debut_date를 출력해보고자 한다.
디폴트는 ASC(ascending)이고, 내림차순으로 출력하려면 DESC(descending)을 SELECT문의 맨 마지막에 적어주면 된다.
-- debut_date가 빠른 순으로 정렬
SELECT mem_id, mem_name, debut_date FROM member ORDER BY debut_date ;
SELECT mem_id, mem_name, debut_date FROM member ORDER BY debut_date DESC ;

이번엔 WHERE절을 추가해서 조건에 해당하는 데이터만을 출력하고 한다.
위의 구문과 같이 WHERE 절은 ORDER BY 절보다 앞에 있어야 한다.
그렇지 않게 쿼리문을 작성하면 syntax error라면서 에러가 나고 데이터가 출력되지 않는다.
-- SQL 구문의 순서가 틀린 경우
SELECT mem_id, mem_name, debut_date, height
FROM member
ORDER BY height DESC
WHERE height >= 164 ; -- 오류가 발생함
-- SQL 구문의 순서가 맞는 경우
SELECT mem_id, mem_name, debut_date, height
FROM member
WHERE height >= 164
ORDER BY height DESC ;
SELECT mem_id, mem_name, debut_date, height
FROM member
WHERE height >= 164
ORDER BY height DESC, debut_date ;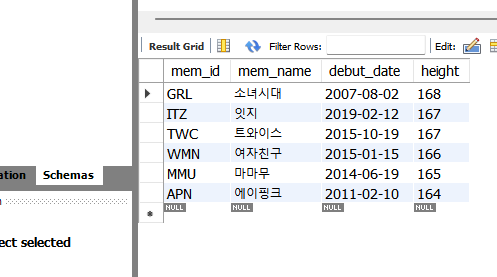

위와 같이 height이 164보다 큰 경우의 그룹들을 키가 큰 순으로 정렬해보았다.
출력의 개수를 제한: LIMIT
테이블에서 모든 행을 출력하지 않고 처음 몇 개만을 출력하고 싶을 때 LIMIT 절을 쓸 수 있다.
LIMIT 절에서 'LIMIT 시작, 개수' 를 쓰면 '시작'에 적힌 행번호에서 '개수'에 적힌 개수만큼을 출력한다는 뜻이다.
-- LIMIT 절
SELECT * FROM member ;
SELECT * FROM member LIMIT 3 ;
SELECT * FROM member LIMIT 0, 3 ; -- :LIMIT 시작, 개수
SELECT * FROM member LIMIT 5, 10 ;
SELECT * FROM member LIMIT 10 OFFSET 5 ; -- 위 구문과 동일
SELECT mem_name, height
FROM member
ORDER BY height DESC
LIMIT 3, 2;
SELECT mem_name, height
FROM member
ORDER BY height DESC
LIMIT 2 OFFSET 3 ;
중복된 결과를 제거: DISTINCT
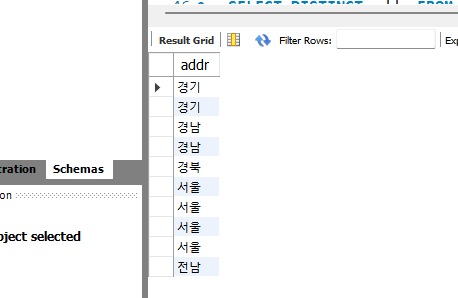
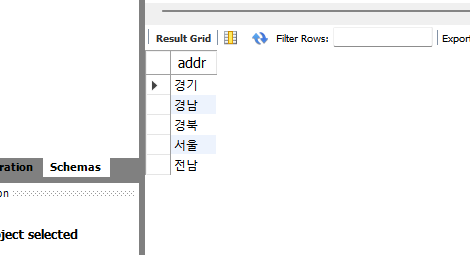
DISTINCT는 조회된 결과에서 중복된 데이터를 1개만 남기게 한다. member 테이블에서 addr만을 조회해보자.
-- DISTINCT 절
SELECT addr FROM member ;
SELECT addr FROM member ORDER BY addr ;
SELECT DISTINCT addr FROM member ORDER BY addr ;

GROUP BY 절
다시 SELECT 절의 형식을 살펴보자. GROUP BY는 WHERE절 이후로 오고, ORDER BY절 이전에 와야한다!
SELECT 열_이름
FROM 테이블_이름
WHERE 조건식
GROUP BY 열_이름 -- **
HAVING 조건식 -- **
ORDER BY 열_이름
LIMIT 숫자
먼저, GROUP BY와 함께 주로 사용되는 집계함수(aggregate function)들은 다음과 같다.
- SUM()
- AVG()
- MIN()
- MAX()
- COUNT()
- COUNT(DISTINCT)
market_db의 buy 테이블에서 회원(mem_id)이 구매한 물품의 개수(amount)를 구하도록 하자.
-- GROUP BY
SELECT * FROM buy ;
SELECT mem_id, amount FROM buy ORDER BY mem_id ;
SELECT mem_id, SUM(amount) FROM buy GROUP BY mem_id ;
SELECT mem_id "회원 아이디", SUM(amount) "총 구매 개수" FROM buy GROUP BY mem_id ;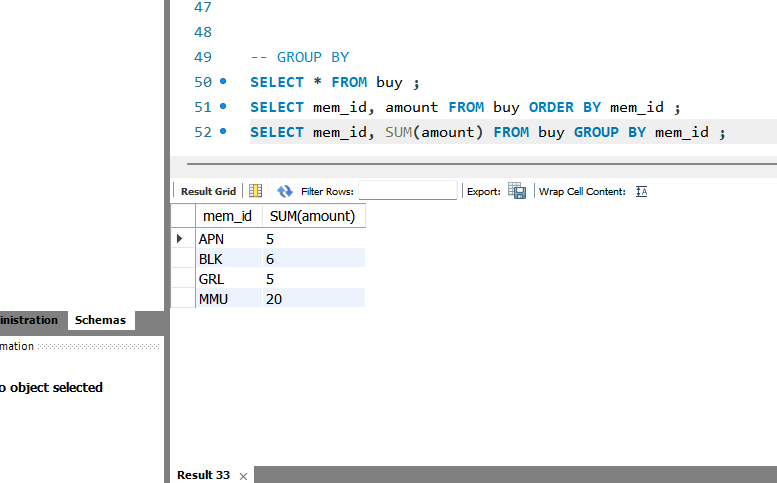
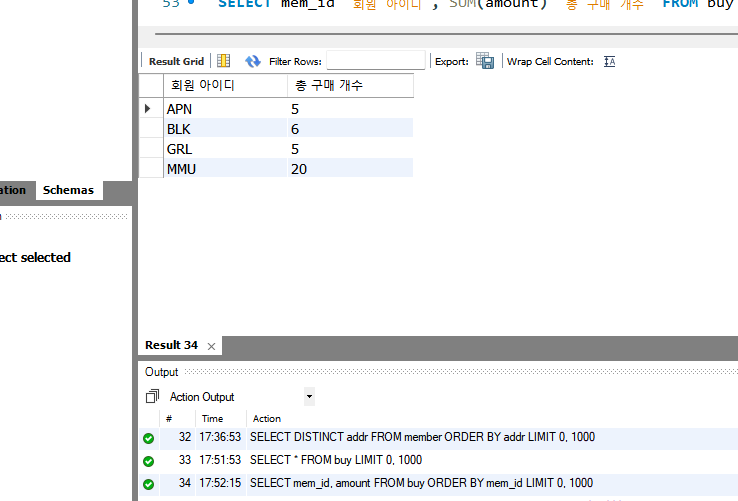
즉, buy 테이블로부터 mem_id 그룹별로 mem_id와 SUM(amount)를 출력한다.
또는 아래와 같이 구매한 금액의 총합을 출력할 수도 있다.
SELECT mem_id "회원 아이디", SUM(amount * price) "총 구매금액" FROM buy GROUP BY mem_id ;
SELECT AVG(amount) FROM buy ;
SELECT mem_id, AVG(amount)
FROM buy
GROUP BY mem_id ;
SELECT COUNT(*) FROM member ; -- member 테이블의 총 데이터 수 (행 개수)
SELECT * FROM member ;
SELECT COUNT(phone1) FROM member ; -- NULL값 제외 데이터 수
HAVING 절
앞서 buy 테이블에서 회원(mem_id)별로 총 구매액을 구해보았다. 여기서 총 구매액이 1000이상인 회원만을 뽑고싶다고 했을 때, 보통 WHERE절을 생각할 수 있다.
-- mem_id 별로 총 구매금액 출력
SELECT mem_id, SUM(amount * price)
FROM buy
GROUP BY mem_id ;
-- 총 구매금액이 1000이 넘는 데이터만 출력
SELECT mem_id, SUM(amount * price)
FROM buy
WHERE SUM(amount * price) > 1000
GROUP BY mem_id ; -- error 발생하지만 WHERE절을 썼을 때 에러가 발생하여 결과가 출력되지 않는다. 그 이유는 WHERE절에 집계함수를 쓸 수 없기 때문이다. 이때 사용할 수 있는 것이 HAVING 절이다.
-- HAVING 절에 집계함수 사용
SELECT mem_id, SUM(amount * price)
FROM buy
GROUP BY mem_id
HAVING SUM(amount * price) > 1000 ;
SELECT mem_id, SUM(amount * price)
FROM buy
GROUP BY mem_id
HAVING SUM(amount * price) > 1000
ORDER BY SUM(amount * price) DESC ;
Reference
혼자 공부하는 SQL, 우재남 지음

'Study > SQL' 카테고리의 다른 글
| [혼공S] CH4-(1). MySQL의 데이터 형식 (0) | 2022.01.23 |
|---|---|
| [혼공S] CH3-(3). 데이터 변경을 위한 SQL 문 (0) | 2022.01.11 |
| [혼공S] CH3-(1). 기본 중에 기본 SELECT ~ FROM ~ WHERE (0) | 2022.01.09 |
| [혼공S] CH2. 실전용 SQL 미리 맛보기 (3) | 2021.12.24 |
| [혼공S] CH1. 데이터베이스와 SQL (0) | 2021.12.08 |



